Apache Spark Use Cases & Applications
Apache Spark was developed by a team at UC Berkeley in 2009. Since then, Apache Spark has seen a very high adoption rate from top-notch technology companies like Google, Facebook, Apple, Netflix etc. The demand has been ever increasing day by day. According to marketanalysis.com survey, the Apache Spark market worldwide will grow at a CAGR of 67% between 2019 and 2022. The Spark market revenue is zooming fast and may grow up $4.2 billion by 2022, with a cumulative market valued at $9.2 billion (2019 – 2022).
As per Apache, “Apache Spark is a unified analytics engine for large-scale data processing”.
Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R. It is also friendly for database developers as it provides Spark SQL which supports most of the ANSI SQL functionality. Spark also has out of the box support for Machine learning and Graph processing using components called MLlib and GraphX respectively. Spark also has support for streaming data using Spark Streaming.
Spark is developed in Scala programming language. Though the majority of use cases of Spark uses HDFS as the underlying data file storage layer, it is not mandatory to use HDFS. It does work with a variety of other Data sources like Cassandra, MySQL, AWS S3 etc. Apache Spark also comes with its default resource manager which might be good enough for the development environment and small size cluster, but it also integrates very well with YARN and Mesos. Most of the production-grade and large clusters use YARN and Mesos as the resource manager.
Spark is being used in more than 1000 organizations who have built huge clusters for batch processing, stream processing, building warehouses, building data analytics engine and also predictive analytics platforms using many of the above features of Spark. Let’s look at some of the use cases in a few of these organizations.
Streaming is basically unstructured data produced by different types of data sources. The data sources could be anything like log files generated while customers using mobile apps or web applications, social media contents like tweets, facebook posts, telemetry from connected devices or instrumentation in data centres. The streaming data is usually unbounded and is being processed as received from the data source.
Then there is Structured streaming which works on the principle of polling data in intervals and then this interval data is processed and appended or updated to the unbounded result table.
Apache Spark has a framework for both i.e. Spark Streaming to handle Streaming using micro batches and DStreams and Structured Streaming using Datasets and Data frames.
Let us try to understand Spark Streaming from an example.
Suppose a big retail chain company wants to get a real-time dashboard to keep a close eye on its inventory and operations. Using this dashboard the management should be able to track how many products are being purchased, shipped and delivered to customers.
Spark Streaming can be an ideal fit here.
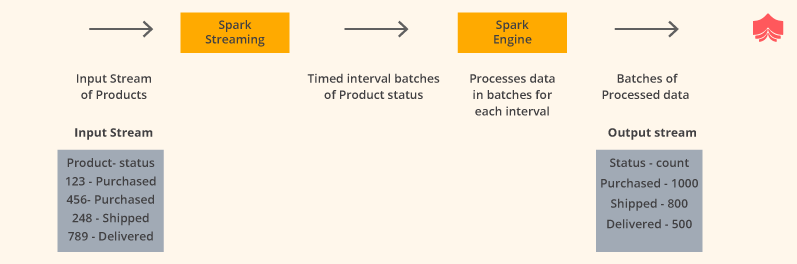
The order management system pushes the order status to the queue(could be Kafka) from where Streaming process reads every minute and picks all the orders with their status. Then Spark engine processes these and emits the output status count. Spark streaming process runs like a daemon until it is killed or error is encountered.
As defined by Arthur Samuel in 1959, “Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed”. In 1997, Tom Mitchell gave a definition which is more specifically from an engineering perspective, “A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”. ML solves complex problems that could not be solved with just mathematical numerical methods or means. ML is not supposed to make perfect guesses. In ML’s domain, there is no such thing. Its goal is to make a prediction or make guesses which are good enough to be useful.
MLlib is the Apache Spark’s scalable machine learning library. MLlib has multiple algorithms for Supervised and Unsupervised ML which can scale out on a cluster for classification, regression, clustering, collaborative filtering. MLlib interoperates with Python’s math/numerical analysis library NumPy and also with R’s libraries. Some of these algorithms are also applicable to streaming data. MLlib helps Spark provide sentiment analysis, customer segmentation and predictive intelligence.
A very common use case of ML is text classification, say for categorising emails. An ML pipeline can be trained to classify emails by reading an Inbox. A typical ML pipeline looks like this. ML is a subject in itself so it is not possible to deep dive here.

Fog Computing is another use case of Apache Spark. To understand Fog computing we need to understand IoT first. IoT basically connects all our devices so that they can communicate with each other and provide solutions to the users of those devices. This would mean huge amounts of data and current cloud computing may not be sufficient to cater to so much data transfer, data processing and online demand of customer’s request.
Fog computing can be ideal here as it takes the work of processing to the devices on the edge of the network. This would need very low latency, parallel processing of ML and complex graph analytical algorithms, all of which are readily available in Apache spark out of the box and can be pick and choose as per the requirements of the processing. So it is expected that as IoT gains momentum Apache spark will be the leader in Fog computing.
Alibaba is the world’s one of the biggest e-commerce players. Alibaba’s online shopping platform generates Petabytes of data as it has millions of users every day doing searches, shopping and placing orders. These user interactions are represented as complex graphs. The processing of these data points is done using Spark’s Machine learning component MLlib and then used to provide better user shopping experience by suggesting products based on choice, trending products, reviews etc.
MyFitnessPal is one of the largest health and fitness lifestyle portals. It has over 80 million active users. The portal helps its users follow and achieve a healthy lifestyle by following a proper diet and fitness regime. The portal uses the data added by users about their food, exercise and lifestyles to identify the best quality food and effective exercise. Using Spark the portal is able to scan through the huge amount of structured and unstructured data and pull out best suggestions for its users.
TripAdvisor has a huge user base and generates a mammoth amount of data every day. It is one of the biggest names in the Travel and Tourism industry. It helps users plan their personal and official trips around the world. It uses Apache Spark to process petabytes of data from user interactions and destination details and gives recommendations on planning a perfect trip based on users choice and preferences. They help users identify best airlines, best prices on hotels and airlines, best places to eat, basically everything needed to plan any trip. It also ranks these places, hotels, airlines, restaurants based on user feedback and reviews. All this processing is done using Apache Spark
Yahoo is known to have one of the biggest Hadoop Cluster and everyone is aware of Yahoo’s contribution to the development of Big Data system. Yahoo is also heavily using Apache Spark Machine learning capabilities to identify topics and news which users are interested in. This is similar to trending tweets or hashtags on Twitter or Facebook. Earlier these Machine Learning algo were developed in C/C++ with thousands of lines of code. While today with Spark and Scala/Pythons these algorithms can be implemented in few hundreds of lines of code. This is a big leap in turnover time as well as code understanding and maintenance. This has been made possible due to Spark to a great extent.
Spark is used in Finance industry across different functional and technology domains.
A typical use case is building a Data Warehouse for batch processing and daily reporting. The Spark data frames abstraction has been used as a generic ingestion platform capable of ingesting data from multiple sources of different formats.
Financial services companies also use Apache Spark MLlib to create and train models for fraud detection. Some of the banks have started using Spark as a tool for classifying text in money transfers.
Some of the companies use Apache spark as log collection, an analysis engine and detection engine.
Let’s look at Spain’s 2nd biggest bank BBVA use case where every money transfer a customer makes goes through an engine that infers a category from its textual description. This engine has been developed in Spark, mixes MLLib and own implementations, and is currently into production serving more than 5M customers daily.

The challenges that the BBVA technology team faced while building this ML were many:
The engineers solved these problems using the Spark MLlib pipeline using some other NLP tools like word2vec.

Healthcare industry is the newest in adopting advanced technologies like big data and machine learning to provide hi-tech facilities to their patients. Apache Spark is penetrating fast and is becoming the heartbeat in the latest Healthcare applications. Hospitals use these Spark enabled healthcare applications to analyze patients medical history to identify possible health issues based on history and learning.
Also, healthcare produces massive amounts of data and to process so much of the data in quick time and provide insights based on that itself was a challenge which Spark solves with ease.
Another very interesting problem in hospitals is when working with Operating Room(OR) scheduling within a hospital setting is that it is difficult to schedule and predict available OR block times. This leads to empty and unused operating rooms leading to longer waiting times for patients for their procedures.
Let’s see a use case. For a basic surgical procedure, it costs around $15-20 per minute. So, OR is a scarce and valuable resource and it needs to be utilized carefully and optimally. OR efficiency differs depending on the OR staffing and allocation, not the workload. So the loss of efficiency means a loss for the patient. So time and management are the utmost importance here.
Spark and MLlib solve the problem by developing a predictive model that would identify available OR time 2 weeks in advance, allows hospitals to confirm waitlist cases two weeks in advance instead of when blocks normally release 4 days out. This OR Scheduling can be done by getting the historical data and running then linear regression model with multiple variables.
This model works because:
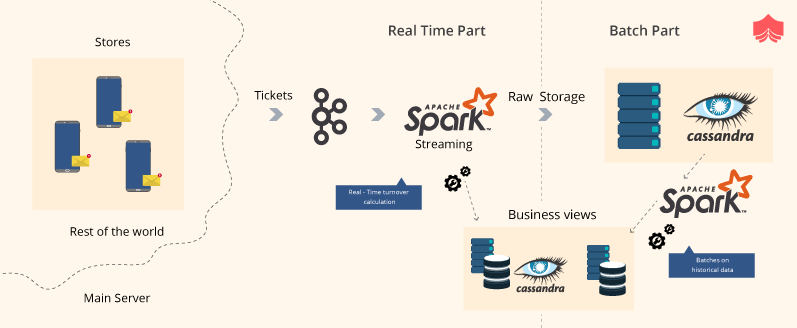
Big retail chains have this usual problem of optimising their supply chain to minimize cost and wastage, improve customer service and gain insights into customer’s shopping behaviour to serve better and in the process optimize their profit.
To achieve these goals these retail companies have a lot of challenges like to keep the inventory up to date based on sales and also to predict sales and inventory during some promotional events and sale seasons. Also, they need to keep a track on customer’s orders transit and delivery. All these pose huge technical challenges. Apache Spark and MLlib is being used by a lot of these companies to capture real-time sales and invoice data, ingest it and then figure out the inventory. The technology can also be used to identify in real-time the order’s transit and delivery status. Spark MLlib analytics and predictive models are being used to predict sales during promotions and sale seasons to match the inventory and be ready for the event. The historical data on customer’s buying behaviour is also used to provide the customer with personalized suggestions and improve customer satisfaction. A lot of stores have started using sensors to get data on customer’s location within the store, their preferences, shopping behaviour, etc to provide on-the-spot suggestions and help to find, buy a product by sending messages, using displays etc.
Airline customer segmentation is a challenging field to understand due to customer’s complex behaviour. Amadeus is one of the main IT solution providers in the airline industry. It has the resources and infrastructure to manage all the ticketing and booking data as well as understanding the Airline needs and market particularities. By combining different data sources produced by different airline systems, they have applied unsupervised machine learning techniques to improve our understanding of customer behaviour.
Challenges in the airline industry are to understand the health of the business:
Traditional approaches for segmentation were based on business intuition and manually crafter rules set. But these approaches have limitations and prejudices which can sometimes be negative for the business. On the contrary, the data-driven approach is resilient against turn-over, prejudices and market change.
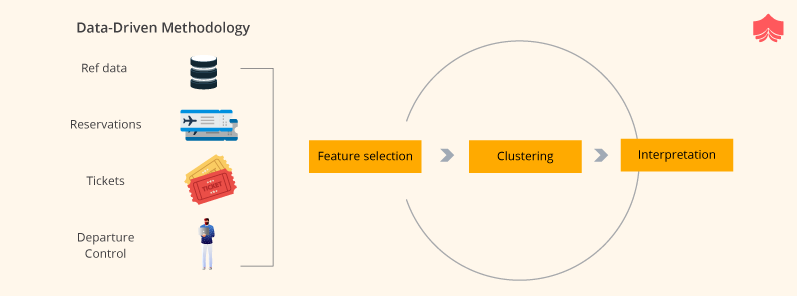
With a data-driven approach and using Spark and MLlib, the model is able to extract actionable insights on typical customer behaviour and intentions. Supervised and supervised learning using Spark MLlib techniques at scale are used to train models for prediction. These are then used to assist the customer in deploying the newfound insights into day-to-day operations.
Media companies Netflix, Hotstar etc are using Apache Spark at the heart of their technology engine to drive their business. When a user turns on Netflix, he is able to see his favourite content playing automatically. This is achieved through recommendation engines built on Machine learning algorithms and Spark MLlib. Netflix uses historical data from users content selection, trains its ML algorithms, tests it offline and then deploys it live and checks if it works in Production as well.
Netflix has built an engine something called Time Travel using Apache Spark and other big data technologies to: Snapshot online services and use the snapshot data offline to generate features and share facts and features between experiments without calling live systems.
If someone is interested in exploring the details of the use case, one can look at the below link:
Apache Spark is spreading its roots everywhere. A common man not related to software industry may not realise it but there are applications running or extracting data from his home environment and processed in Spark to make his life better and easier. An example we will discuss below is the British Gas.
British Gas is a 200-year-old company. Connected Homes is BG’s IoT “startup”. It is a leader in the UK’s connected home market. Connected Homes is trying to predict the usage consumption patterns of the electricity, gas at the homes and provide consumers with insights so they can smartly use their devices and reduce energy consumption and save energy and money. Connected homes use Apache Spark at the core of its Data Engineering and ML engine.
The challenges are there are millions of electric and gas meters and the meters are read every 30 minutes.
There are:
Apache Spark MLlib is used to apply machine learning to these data for disaggregation, similar home comparison and smart meters used in indirect algorithms for non-smart customers.
The analytics engine is used to show customers how they have spent energy, what are their top 3 spends, how can they reduce their energy consumption by showing patterns from smart consumers and smart meters etc. This gives customers a lot of insight and educates customers on optimally using energy at their homes.
Online Gaming industry is another beneficiary of the Apache Spark technology.
Riot Games uses Spark for Combating abusive language in chat in the team games. The challenges in online gaming are:
To solve this the game developers tried to predict the words used by the gamers in the context of the game or the scenario. They used the “Word2Vec” a neural model which has 256 dimensions embedding months of chat logs. Each word in the chat is document split in spaces and lowercase. The model was trained on NLP for acronyms, short forms, colloquial words etc and the deviations could be huge. The team built a model trained to predict bad/toxic language. The gaming company has 100+ million users every month and so the data is huge. They used Spark MLlib to train their models using different algorithms, one of them Logistic Regression Random Forest Gradient Boosted Trees. The results were impressive for them as they tuned their models for better precision.
Many of the companies across industries have been benefiting from Apache Spark. The reasons could be different:
Apache Spark is beneficial for small as well as large enterprise. Spark offers a complete solution to many of the common problems like ETL and warehousing, Stream data processing, common use case of supervised and unsupervised learning for data analytics and predictive modelling. So with Apache Spark, the technology team does not require to look out for different technology stack and multiple vendors for a solution. This reduces the learning curve for additional development and maintenance. Also, since Spark has support for multiple languages Scala, Java, Python & R, it is easy to find developers.
Though there are so many benefits of Apache Spark as we have seen above, there are few limitations which Apache Spark has. We should be aware of these limitations before we decide to adopt any technology.
We have seen the wide impact and use cases if Apache Spark. So we know that Spark has become a buzzword these days. We should now also understand why we should learn Spark.
One can look at an old survey by Databricks to understand the importance and impact of Apache Spark by 2016. By 2019 these number would have grown much bigger.
Conclusion
Apache Spark has capabilities to process huge amount of data in a very efficient manner with high throughput. It can solve problems related to batch processing, near real-time processing, can be used to apply lambda architecture, can be used for Structured streaming. Also, it can solve many of the complex data analytics and predictive analytics problems with the help of the MLlib component which comes out of the box. Apache Spark has been making a big impact on the whole data engineering and data science gamut at scale.
Credit card transactions of a cardholder can be captured over a period of time to categorize user’s spending habits. Models can be developed and trained to predict any anomaly in the card transaction and along with Spark streaming and Kafka in real time.
Spark interfaces with programming languages like R, Python, SQL and Scala which caters to a bigger set of developers and users for interactive analysis.Spark also came up with Structured Streaming in version 2.0 which can be used for interactive analysis with live data as well as join the live data with batch data output to get more insight into the data. Structured streaming in future has the potential to boost Web Analytics by allowing users to query user’s live web session. Even machine learning can be applied to live session data for more insights.
With Spark, even the processing can be scaled horizontally by adding machines to the Spark engine cluster.These migrated applications embed the Spark engine and offer a web UI to allow users to create, run, test and deploy jobs interactively. Jobs are primarily written in native Spark SQL or other flavours of SQL. These Spark clusters have been able to scale to process many terabytes of data every day and the clusters can be hundreds to thousands of nodes.
Research & References of Apache Spark Use Cases & Applications|A&C Accounting And Tax Services
Source
0 Comments