What are Decision Trees in Machine Learning (Classification And Regression)
Machine Learning is an interdisciplinary field of study and is a sub-domain of Artificial Intelligence. It gives computers the ability to learn and infer from a huge amount of homogeneous data, without having to be programmed explicitly.
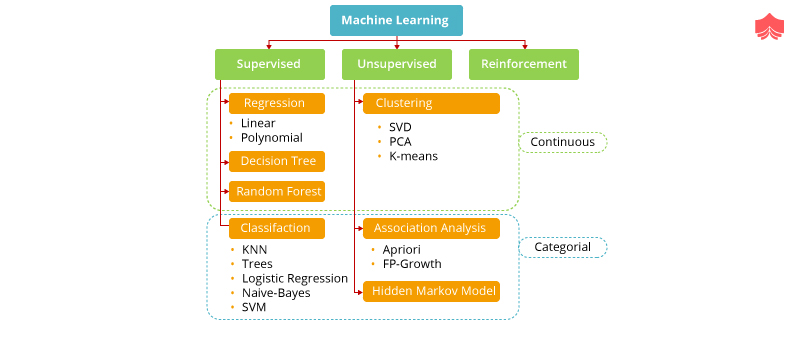
Types of Machine Learning: Machine Learning can broadly be classified into three types:



Classification is the process of determination/prediction of the category to which a data-point may belong to. It is the process by which a Supervised Learning Algorithm learns to draw inference from the features of a given dataset and predict which class or group or category does the particular data point belongs to.
Example of Classification: Let’s assume that we are given a few images of handwritten digits (0-9). The problem statement is to “teach” the machine to classify correctly which image corresponds to which digit. A small sample of the dataset is given below:

The machine has to be thus trained, such that, when given an input of any such hand-written digit, it has to correctly classify the digits and mention which digit the image represents. This is classed classification of hand-written digits.
Looking at another example which is not image-based, we have 2D data (x1 and x2) which is plotted in the form of a graph shown below.

The red and green dots represent two different classes or categories of data. The main goal of the classifier is that given one such “dot” of unknown class, based on its “features”, the algorithm should be able to correctly classify if that dot belongs to the red or green class. This is also shown by the line going through the middle, which correctly classifies the majority of the dots.
Applications of Classification: Listed below are some of the real-world applications of classification Algorithms.
Regression is also a type of supervised learning. Unlike classification, it does not predict the class of the given data. Instead, it predicts the corresponding values of a given dataset based on the “features” it encounters.
Example of Regression: For this, we will look at a dataset consisting of California Housing Prices. The contents of this dataset are shown below.

Here, there are several columns. Each of the columns shows the “features” based on which the machine learning algorithm predicts the housing price (shown by yellow highlight). The primary goal of the regression algorithm is that, given the features of a given house, it should be able to correctly estimate the price of the house. This is called a regression problem. It is similar to curve fitting and is often confused with the same.
Applications of Regression: Listed below are some of the real-world applications of regression Algorithms.
In order to get started with Decision Trees, it is important to understand the basic building blocks of decision trees. Hence, we start building the concepts slowly with some basic theory.
Definition: It is a commonly used concept in Information Theory and is a measure of “purity” of an arbitrary collection of information.
Mathematical Equation:
Here, given a collection S, containing positive and negative examples, the Entropy of S is given by the above equation, where, p represents the probability of occurrence of that example in the given data.
In a more generalized form, Entropy is given by the following equation:

Example: As an example, a sample S is taken, which contains 14 data samples and includes 9 positive and 5 negative samples. The same is denoted by the mathematical notion: [9+, 5–].
Thus, Entropy of the given sample can be calculated as follows:
Definition: With the knowledge of Entropy, the amount of relevant information that is gained form a given random sample size can be calculated and is known as Information Gain.
Mathematical Equation:

Here, the Gain (S, A) is the Information Gain of an attribute A relative to a sample S. The Values(A) is a set of all possible values for attribute A.
Example: As an example, let’s assume S is a collection of 14 training-examples. Here, in this example, we will consider the Attribute to be Wind and the values of that corresponding attribute will be Weak and Strong. In addition to the previous example information, we will assume that out of the previously mentioned 9 positives and 5 negative samples, 6 positive and 2 negative samples have the value of the attribute Wind=Weak, and the remaining have Wind=Strong. Thus, under such a circumstance, the information gained by the attribute Wind is shown below.

Introduction: Since we have the basic building blocks out of the way, let’s try to understand what exactly is a Decision Tree. As the name suggests, it is a Tree which is developed based on certain decisions taken by the algorithm in accordance with the given data that it has been trained on.
In simple words, a Decision Tree uses the features in the given data to perform Supervised Learning and develop a tree-like structure (data structure) whose branches are developed in such a way that given the feature-set, the decision tree can predict the expected output relatively accurately.
Example: Let us look at the structure of a decision tree. For this, we will take up an example dataset called the “PlayTennis” dataset. A sample of the dataset is shown below.

In summary, the target of the model is to predict if the weather conditions are suitable to play tennis or not, as guided by the dataset shown above.
As it can be seen in the dataset, it contains certain information (features) for each day. In this, we have the feature-attributes: Outlook, Temperature, Humidity and Wind and the target-attribute PlayTennis. Each of these attributes can take up certain values, for example, the attribute Outlook has the values Sunny, Rain and Overcast.
With a clear idea of the dataset, jumping a bit forward, let us look at the structure of the learned Decision Tree as developed from the above dataset.

As shown above, it can clearly be seen that, given certain values for each of the attributes, the learned decision tree is capable of giving a clear answer as to whether the weather is suitable for Tennis or not.
Algorithm: With the overall intuition of decision trees, let us look at the formal Algorithm:
Connecting the dots: Since the overall idea of decision trees have been explained, let’s try to figure out how Entropy and Information Gain fits into this entire process.
Entropy (E) is used to calculate Information Gain, which is used to identify which attribute of a given dataset provides the highest amount of information. The attribute which provides the highest amount of information for the given dataset is considered to have more contribution towards the outcome of the classifier and hence is given the higher priority in the tree.
For Example, considering the PlayTennis Example, if we calculate the Information Gain for two corresponding Attributes: Humidity and Wind, we would find that Humidity plays a more important role in deciding whether to play tennis or not. Hence, in this case, Humidity is considered as a better classifier. The detailed calculation is shown in the figure below:

With the basic idea out of the way, let’s look at where decision trees can be used:
Listed below are some of the advantages of Decision Trees:
Listed below are some of the limitations of Decision Trees:
With the theory out of the way, let’s look at the practical implementation of decision tree classifiers and regressors.
In order to conduct classification, a diabetes dataset from Kaggle has been used. It can be downloaded here.

The highlighted column is the target value that the model is expected to predict, given the parameters.

In order to conduct classification, a diabetes dataset from Kaggle has been used. It can be downloaded here.
The graph that is thus generated is shown below. Here we can clearly see that for a simple dataset when we used max_depth=5 (green), the model started to overfit and learned the patterns of the noise along with the sine wave. Such kinds of models do not perform well. Meanwhile, for max_depth=3 (blue), it has fitted the dataset in a better way when compared to the other one.

Conclusion
In this article, we tried to build an intuition, by starting from the basics of the theory behind the working of a decision tree classifier. However, covering every aspect of detail is beyond the scope of this article. Hence, it is suggested to go through this book to dive deeper into the specifics. Further, moving on, the code snippets introduces the “Hello World” of how to use both, real-world data and artificially generated data to train a Decision Tree model and predict using the same. This will allow any novice to get an overall balanced theoretical and practical idea about the workings of Classification and Regression Trees and their implementation.
- A ← the attribute from Attributes that best classifies the Samples
- The decision attribute for Root ← A
- For each possible value of A:
- Add a new tree branch below Root, corresponding to the test A = vi
- Let the Samplesvi be the subset of Samples that have value vi for A
- If Samplesvi is empty:
- Then below the new branch add a leaf node with the label = most common value of Target_attribute in the samples
- Else below the new branch add the subtree:
- ID3(Samplesvi, Target_attribute, Attributes – {A})
- Add a new tree branch below Root, corresponding to the test A = vi
- Let the Samplesvi be the subset of Samples that have value vi for A
- If Samplesvi is empty:
- Then below the new branch add a leaf node with the label = most common value of Target_attribute in the samples
- Else below the new branch add the subtree:
- ID3(Samplesvi, Target_attribute, Attributes – {A})
- Then below the new branch add a leaf node with the label = most common value of Target_attribute in the samples
- Else below the new branch add the subtree:
- ID3(Samplesvi, Target_attribute, Attributes – {A})
Research & References of What are Decision Trees in Machine Learning (Classification And Regression)|A&C Accounting And Tax Services
Source
0 Comments