Introduction to the Machine Learning Stack
Arthur Samuel coined the term Machine Learning or ML in 1959. Machine learning is the branch of Artificial Intelligence that allows computers to think and make decisions without explicit instructions. At a high level, ML is the process of teaching a system to learn, think, and take actions like humans.
Machine Learning helps develop a system that analyses the data with minimal intervention of humans or external sources. ML uses algorithms to analyse and filter search inputs and correspondingly displays the desirable outputs.
Machine Learning implementation can be classified into three parts:
Stacking in generalised form can be represented as an aggregation of the Machine Learning Algorithm. Stacking Machine Learning provides you with the advantage of combining the meta-learning algorithm with training your dataset, combining them to predict multiple Machine Learning algorithms and machine learning models.
Stacking helps you harness the capabilities of a number of well-established models that perform regression and classification tasking.
When it comes to stacking, it is classified into 4 different parts:
A generalisation of Stacking: Generalisation is a composition of numerous Machine Learning models performed on a similar dataset, somewhat similar to Bagging and Boosting.
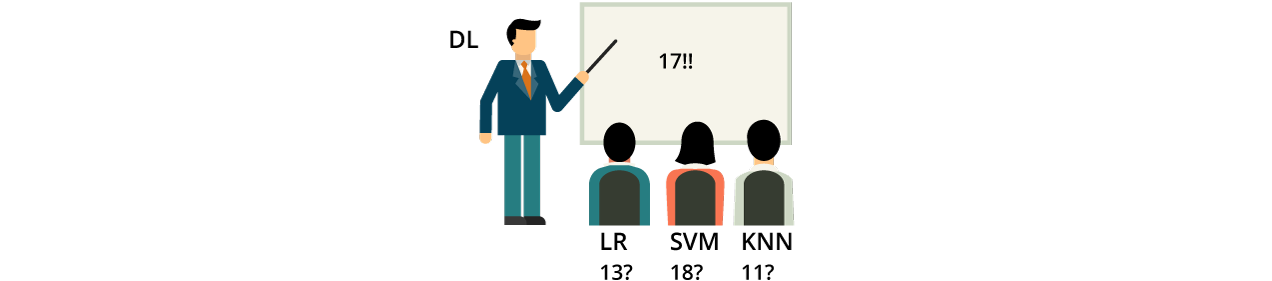
The basic technique of Stacking in Machine Learning;
Dive deeper into the Machine Learning engineering stack to have a proper understanding of how it is used and where it is used. Find out the below list of resources:
Keras: Keras is an open-source library, which provides you with the open interface for Artificial Intelligence and Artificial Neural Network using Python. It helps in designing API for human convenience and follows best practices to reduce cost and move toward cognitive load maintenance.
It acts as an interface between the TensorFlow library and dataset. Keras was released in 2015. It has a vast ecosystem which you can deploy anywhere. There are many facilities provided by Keras which you can easily access with your requirements.
CERN uses Keras, NASA, NIH, LHC, and other scientific organisations to implement their research ideas, offer the best services to their client, and develop a high-quality environment with maximum speed and convenience.
Keras has always focused on user experience offering a simple APIs environment. Keras has abundant documentation and developer guides which are also open-source, which anyone in need can refer to.
Luigi: This is a Python module that supports building batch jobs with the background of complex pipelining. Luigi is internally used by Spotify, and helps to run thousands of tasks daily, that are organised in the form of the complex dependency graph. Luigi uses the Hadoop task as a prelim job for the system. Luigi being open-source has no restrictions on its usage by users.
The concept of Luigi is based on a unique contribution where there are thousands of open-source contributions or enterprises.
Luigi supports cascading Hive and Pig tools to manage the low level of data processing and bind them together in the big chain together. It takes care of workflow management and task dependency.
Pandas: If you want to become a Data Scientist, then you must be aware of Pandas–a favourite tool with Data Scientists, and the backbone of many high-profile big data projects. Pandas are needed to clean, analyse, and transform the data according to the project’s need.
Pandas is a fast and open-source environment for data analysis and managing tools. Pandas is created at the top of the Python language. The latest version of Pandas is Pandas 1.2.3.
When you are working with Pandas in your project, you must be aware of these scenarios
Pandas provide an open-source environment and documentation where you can raise your concern, and they will identify the solution to your problem.
PyTorch: PyTorch is developed in Python, which is the successor of the python torch library. PyTorch is also an open-source Machine learning Library; the main use of PyTorch is found in computer vision, NLP, and ML-related fields. It is released under the BSD license.
Facebook and Convolutional Architecture operate PyTorch for Fast Feature Embedding (CAFFE2). Other major players are working with it like Twitter, Salesforce, and oxford.
PyTorch has emerged as a replacement for NumPy, as it is faster than NumPy in performing the mathematical operations, array operations and provides the most suitable platform.
PyTorch provides a more pythonic framework in comparison to TensorFlow. PyTorch follows a straightforward procedure and provides a pre-prepared model to perform a user-defined function. There is a lot of documentation you can refer to at their official site.
Key Features
Spark: Spark or Apache Spark is a project from Apache. It is an open-source, distributed, and general-purpose processing engine. It provides large-scale data processing for big data or large datasets. Spark provides you support for many backgrounds like Java, Python, R, or SQL, and many other technologies.
Leverage data to a variety of sources
Scikit- learn: Scikit-Learn also known as sklearn, is a free and open-source software Machine Learning Library for Python. Scikit-Learn is the result of a Google summer Code project by David Cournapeau. Scikit-Learn makes use of NumPy for an operation like array operation, algebra, and high performance.
The latest version of Scikit-Learn was deployed in Jan 2021, Version of Scikit-Learn 0.24.
The benefits of Scikit-Learn include
Scikit-Learn is used in
TensorFlow: TensorFlow is an open-source end-to-end software library used for numerical computation. It does graph-based computations quickly and efficiently leveraging the GPU (Graphics Processing Unit), making it seamless to distribute the work across multiple GPUs and computers. TensorFlow can be used across a range of projects with a particular concentration on the training dataset and Neural network.
The benefits of TensorFlow
Stacking provides many benefits over other technologies.
If you are working in Python, you must be aware of the K-folds clustering or k-mean clustering, and we perform stacking using the k fold method.
Blending is a subtype of stacking.
Installing libraries in Python is an easy task; you just require some pre-requisites.
Use pip for installing libraries and packages into your system.
Conclusion
To understand the basics of data science, machine learning, data analytics, and artificial intelligence, you must be aware of machine learning stacking, which helps store and manage the data and large datasets.
There is a list of open-source models and platforms where you can find the complete documentation about the machine learning stacking and required tools. This machine learning toolbox is robust and reliable. Stacking uses the meta-learning model to develop the data and store them in the required model.
Stacking has the capabilities to harness and perform classification, regression, and prediction on the provided dataset. It helps to constitute regression and classification predictive modelling. The model has been classified into two models, level 0, known as the base model, and the other model-level 1, known as a meta-model.
Keras: Keras is an open-source library, which provides you with the open interface for Artificial Intelligence and Artificial Neural Network using Python. It helps in designing API for human convenience and follows best practices to reduce cost and move toward cognitive load maintenance.
Luigi: This is a Python module that supports building batch jobs with the background of complex pipelining. Luigi is internally used by Spotify, and helps to run thousands of tasks daily, that are organised in the form of the complex dependency graph. Luigi uses the Hadoop task as a prelim job for the system. Luigi being open-source has no restrictions on its usage by users.
Pandas: If you want to become a Data Scientist, then you must be aware of Pandas–a favourite tool with Data Scientists, and the backbone of many high-profile big data projects. Pandas are needed to clean, analyse, and transform the data according to the project’s need.
PyTorch: PyTorch is developed in Python, which is the successor of the python torch library. PyTorch is also an open-source Machine learning Library; the main use of PyTorch is found in computer vision, NLP, and ML-related fields. It is released under the BSD license.
Spark: Spark or Apache Spark is a project from Apache. It is an open-source, distributed, and general-purpose processing engine. It provides large-scale data processing for big data or large datasets. Spark provides you support for many backgrounds like Java, Python, R, or SQL, and many other technologies.
Scikit- learn: Scikit-Learn also known as sklearn, is a free and open-source software Machine Learning Library for Python. Scikit-Learn is the result of a Google summer Code project by David Cournapeau. Scikit-Learn makes use of NumPy for an operation like array operation, algebra, and high performance.
TensorFlow: TensorFlow is an open-source end-to-end software library used for numerical computation. It does graph-based computations quickly and efficiently leveraging the GPU (Graphics Processing Unit), making it seamless to distribute the work across multiple GPUs and computers. TensorFlow can be used across a range of projects with a particular concentration on the training dataset and Neural network.
- Use – python –version on your command line to check if Python is installed in your system.
- Python -m pip – – version
- Python -m pip install – – upgrade pip setuptools wheel
Research & References of Introduction to the Machine Learning Stack|A&C Accounting And Tax Services
Source
0 Comments